Mathematical description
Looking at the law of distribution, we can understand what is the probability of an event, we can say what is the probability that a group of events will occur, and in this article we will look at how to translate our conclusions "by eye" into a mathematically sound statement.
An extremely important definition: mathematical expectation is the area under the distribution graph. If we are talking about a discrete distribution - this is the sum of events multiplied by the corresponding probabilities, also known as moment:
(2) E(X)=Σ(pi•Xi) E - from the English word Expected (waiting)
For mathematical expectation, the equalities are valid:
(3) E(X + Y) = E(X) + E(Y)
(4) E(X•Y) = E(X) • E(Y)
Moment of degree k:
(5) νk = E(Xk)
The central moment of degree k:
(6) μk = E[X - E(X)]k
Average value
Average value (μ) the distribution law is the mathematical expectation of a random variable (a random variable is an event), for example, how many average visitors come to the store per hour:
| Number of visitors | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| Number of observations | 146 | 9 | 108 | 40 | 33 | 28 | 36 |
| Table 1. Number of visitors per hour | |||||||
To find the average value of all the results, you need to add everything together and divide by the number of results:
μ = (146 • 0 + 9 • 1 + 108 • 2 + 40 • 3 + 33 • 4 + 28 • 5 + 36 • 6) / 400 = 833/400 = 2.08
We can do the same using formula 2:
μ = M(X) = Σ(Xi•pi) = 0 • 0.37 + 1 • 0.02 + 2 • 0.27 + 3 • 0.1 + 4 • 0.08 + 5 • 0.07 + 6 • 0.09 = 2.08 Moment of the first degree, formula (5)
Actually, formula 2 is the arithmetic mean of all values
Total: on average, 2.08 visitor per hour
| Number of visitors | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| Probability (%) | 36.5 | 2.3 | 27 | 10 | 8.3 | 7 | 9 |
| Table 2. The law of distribution of the number of visitors | |||||||
Deviation from the mean
Look at this distribution, we can assume that on average the random variable is 100±5, because it seems that there are incomparably more such values than those that are less than 95 or more than 105:
The average value according to the formula (2): μ = 99.95, but how to calculate how far all values are from the average? You should be the entry 100±5 is familiar. To get this value ±, we need to define a range of values around the mean. And we could use the "difference" between the mean and random variables as a distance measure:
(7) xi - μ
but the sum of such distances, and therefore any derivative of this number, will be zero, so the square of the differences was chosen as the measure between the values and the average value:
(8) (xi - μ)2
Accordingly, the average distance value is the mathematical expectation of the squares of the distance:
(9) σ2 = E[(X - E(X))2] Since the probabilities of any distance are equal, the probability of each of them is 1/n, from where: (10) σ2 = E[(X - E(X))2] = ∑[(Xi - μ)2]/n It is also the formula of the central moment (6) of the second degree
σ is squared, because instead of distances we took the square of distances. σ2 is called variance. The root of the variance it is called the mean square deviation, or the standard deviation, and it is used as a measure of the spread:
(11) μ±σ
(12) σ = √(σ2) = √[∑[(Xi - μ)2]/n]
Returning to the example, let's calculate the standard deviation for graph 2:
σ = √(∑(x-μ)2/n) = √{[(90 - 99.95)2 + (91 - 99.95)2 + (92 - 99.95)2 + (93 - 99.95)2 + (94 - 99.95)2 + (95 - 99.95)2 + (96 - 99.95)2 + (97 - 99.95)2 + (98 - 99.95)2 + (99 - 99.95)2 + (100 - 99.95)2 + (101 - 99.95)2 + (102 - 99.95)2 + (103 - 99.95)2 + (104 - 99.95)2 + (105 - 99.95)2 + (106 - 99.95)2 + (107 - 99.95)2 + (108 - 99.95)2 + (109 - 99.95)2 + (110 - 99.95)2]/21} = 6.06
So, for graph 2 we got:
X = 99.95±6.06 ≈ 100±6, which is slightly different from the received "by eye"
Quantile
Graph 4. Distribution function. 4-quantile or quartile
Graph 5. Distribution function. 0.34-quantile
To analyze the distribution function, the concept of quantile was introduced. A quantile is a random variable at a given probability level, i.e.: a quantile for a probability level of 50% is a random variable on a probability density graph that has a probability of 50%. In the example with graph 3, the quantile of the level 0.5 = 99 (the nearest value, since the distribution is discrete and events with a value of 99.3 simply do not exist)
- 2-quantile median
- 4-quantile - quartile
- 10-quantile - decile
- 100-quantile - percentile
That is, if we are talking about a decile (10-quantile), it means that we have divided the graph into 10 parts, which corresponds to nine lines, and for each decile we have found the value of a random variable.
Also, the notation x-quantile is used, where x is a fractional number, for example, 0.34-quantile, such an entry means the value of a random variable when p = 0.34.
For a discrete distribution, the quantile must be chosen as follows: the quantile guarantees the probability, therefore, if the calculated the quantile does not match one and the values, it is necessary to choose a smaller value.
For example, we have a discrete distribution of 1325 values, given that each value has a probability of 1/1325, the 10th quantile will have a value that does not exceed 10% of 1325, that is, a value equal to or less than 132.5.
Building intervals
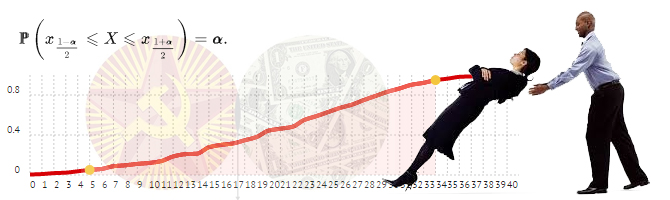
Quantiles are used to construct confidence intervals, which are necessary for the study of statistics of more than one specific event (for example, interest is a random number = 98), and for a group of events (for example, interest is a random number between 96 and 99). The confidence interval is of two types: one-sided and two-sided. The parameter of the confidence interval is the confidence level. The confidence level means the percentage of events that can be considered successful.
Two-way confidence interval
The two-way confidence interval is constructed as follows: we set the significance level, for example, 10%, and select an area on the graph so that 90% of all events will fall into this area. Since the interval is two-sided, we cut off 5% on each side, i.e. we are looking for the 5th percentile, the 95th percentile and the values of the random variable between them will be the confidence area, values outside the confidence area are called "critical area"
Confidence interval
The left-sided and right-sided confidence intervals are constructed similarly to the two-sided one: for the left-sided interval, we find the percentile of the level ['one' minus 'significance level']. Thus, to construct a confidence left-sided interval of the significance level of 4%, we need to find the fourth percentile and everything on the right is a confidence interval, everything on the left is a critical area.
Total
The average value is the mathematical expectation of a random variable, found by the formula:
μ = E(X) = Σ(pi•Xi)
The standard deviation is the mathematical expectation of the distance of values from the average, is found by the formula:
σ = √(σ2) = √[∑[(Xi - μ)2]/n]
n-quantile - division of the distribution function into n equal segments, the main types of quantiles:
- 2-quantile - median
- 4-quantile -quartiles
- 10-quantile - deciles
- 100-quantile - percentiles
The confidence interval of the α level is a section of the probability function containing α of all possible values. The two-way confidence interval is constructed by clipping (1-α)/2 on the right and left. The left- sided and right-sided confidence intervals are constructed by clipping areas (1-α) left and right respectively.
Construct a distribution series
Suppose we have 100 values and all are different, for example: the body weight of Somali pirates. It is inconvenient to process such a set of data, we cannot even present them on a regular graph. Therefore, we need to categorize the available data and for this we do the following:
Let's write down our data in the table:
| 73 | 87 | 78 | 93 | 76 | 112 | 80 | 101 | 105 | 60 |
| 70 | 58 | 61 | 95 | 72 | 66 | 60 | 100 | 63 | 78 |
| 106 | 113 | 77 | 109 | 116 | 107 | 67 | 101 | 114 | 55 |
| 56 | 116 | 75 | 64 | 94 | 96 | 66 | 70 | 54 | 74 |
| 76 | 95 | 79 | 88 | 95 | 101 | 108 | 100 | 99 | 77 |
| 57 | 87 | 86 | 104 | 101 | 92 | 90 | 89 | 65 | 65 |
| 89 | 80 | 65 | 116 | 98 | 86 | 92 | 75 | 92 | 87 |
| 87 | 88 | 104 | 114 | 105 | 113 | 63 | 100 | 59 | 110 |
| 108 | 101 | 97 | 75 | 104 | 90 | 78 | 84 | 89 | 97 |
| 86 | 84 | 67 | 92 | 92 | 80 | 88 | 68 | 112 | 63 |
| Table 3. Weight of Somali pirates | |||||||||
We will divide the data into groups, to begin with, I suggest splitting it into nine intervals:
Find out the maximum and minimum values, subtract them from each other and divide by the number intervals - received segments:
Maximum value: 116
Minimum value: 54
Difference: 116 - 54 = 62
Interval length: 62 / 9 = 6.89
Now let's count the number of pirates (weights, I mean) in each interval:
| # | Interval | Number of elements |
|---|---|---|
| 1. | 54 - 60.89 | 8 |
| 2. | 60.89 - 67.78 | 12 |
| 3. | 67.78 - 74.67 | 6 |
| 4. | 74.67 - 81.56 | 14 |
| 5. | 81.56 - 88.45 | 12 |
| 6. | 88.45 - 95.34 | 15 |
| 7. | 95.34 - 102.23 | 13 |
| 8. | 102.23 - 109.12 | 10 |
| 9. | 109.12 - 116.01 | 10 |
| Table 4. Number of elements in intervals | ||
Voila, our distribution on the graph:
Bonus
It is better to take the intervals as integers, so if with the selected number of intervals the size comes out as a non-integer, then you can expand the range of values, for example:
The interval value is 6.89, the number is not an integer, so pushing back the upper bound:
The remainder of the division: [(116 - 54) / 9] = 8
Move to: 1
New range: [54;117]
The range can be moved both up and down, but preferably in both directions.
Tip
It is customary to divide the distribution into 7-8 intervals, but in each specific situation You can choose a great number of intervals, however, as well as make them of different lengths.
List of parameters
So, here is a list of the main parameters of the discrete distribution law:
| Name | Symbol | Formula |
|---|---|---|
| Mathematical expectation (average) | E(X) | Σ(pi•Xi) |
| Central moment (standard deviation) | σx | σ = √(σ2) = √[∑[(Xi - μ)2]/n] |
| Interval length | R | max(x) - min(x) |
| Fashion | mo | max P(x = mo) |
| 1st quantile | - | F(x) = 0.25 |
| Median | me | F(x) = 0.5 |
| Decile | - | F(x) = 0.1 |
| Table 5. Basic parameters of the discrete distribution law | ||
Histogram template in OpenOffice Calc
File histogram_mock.ods contains a histogram construction template.